We created Trellis to democratize LLM inference without making compromises on the data privacy of its users. Towards that goal, we built a system that users can deploy on hardware they already own and operate, i.e. laptops, workstations and servers alike.
To meet users where they are, we must accommodate more or less performant hardware, and therefore take optimization opportunities whenever possible.
In this post, we will focus on how we optimized the prefill phase of LLM inference in Trellis. We'll start by giving a brief background on the problem, discuss our implementation of a caching strategy that is relevant for chat-based and agentic LLM sessions, and conclude by showing some benchmark results.
LLM prefill and the KV cache
The compute nodes of a Trellis grid perform the numerical operations of a LLM transformer block (attention, linear layers etc.). Before the numerics can evaluate a result (ie. sample the next token), we must populate all the operands with coefficients; this is the prefill phase of LLM inference, and it is compute-bound. Concretely, to produce token \(t+1\) , attention needs the keys and values (the projected embeddings) of every prior token (tokens \(0 .. t\) ).
The first key observation: in autoregressive generation, a sampled token is appended to the already generated ones, and the combined sequence is fed back into the model as input. This fact, combined with the causal attention mask, means that the embeddings (and therefore the K and V matrices) at position \(i < j\) do not depend on those at later positions \(k \geq j\) , and can therefore be cached , append-only, while producing all later tokens.
Prefix caching with RadixAttention
The second key observation follows from the actual use of LLMs, i.e. chat sessions where a system prompt precedes the user request: repeated LLM requests based on the same template must prefill the model with a common prefix string, which means we can precompute and cache all the token embeddings of the system prompt. Not only that, but in principle we could cache all prefixes of a prompt, if we know these will be reused across requests. The key insight of RadixAttention was to use a specialized data structure (a radix tree) that minimizes storage in the common case when string prefixes share whole substrings (e.g. given the strings "hello my name is Alice", "hello my name is Bob", a radix tree would only store 3 entries: "hello my name is ", "Alice", "Bob").
RadixAttention in Trellis
In a Trellis grid, there can be multiple nodes making concurrent inference requests, which in turn are served by multiple nodes, each holding one or more transformer blocks. As such, the KV caching mechanism also serves as a concurrency mechanism, since unrelated requests may share a prefix (e.g if a team reuses the same system prompt).
Our implementation of the RadixAttention KV cache is block-paged: K/V activations are stored in fixed-size blocks of token embeddings, drawn from a shared pool, and each session holds an ordered list of block IDs rather than a contiguous array. When two sessions share a prefix, the second session acquires the existing prefix blocks (a refcount bump) instead of allocating and recomputing fresh ones.
Benchmarks
Setup and definitions
All benchmarks below run TinyLlama 1.1B Q4_0 in-process on a single Mac M1, with synthetic prompts. The recurring parameters are:
- L — prompt length, in tokens.
- D — decode budget: the number of tokens generated per session.
- N — number of concurrent decode sessions. We use one shared "system prompt" that is warmed once, plus N divergent user suffixes, one per session.
- φ (phi) — the shared-prefix fraction: what fraction of each prompt is the common prefix. φ=0.5 means the first half of every prompt is identical across calls. Note that φ is block-quantized: internally the shared region is rounded to a whole number of 32-token blocks (
prefixBlocks = round(φ·L/32)), so the realized φ snaps to multiples of 32/L. - op — one full benchmark iteration: building a fresh inference pipeline, warming the shared prefix, and running all N sessions to completion. So "allocations/op" is the heap traffic of an entire iteration, not of a single token.
Throughput and memory allocation
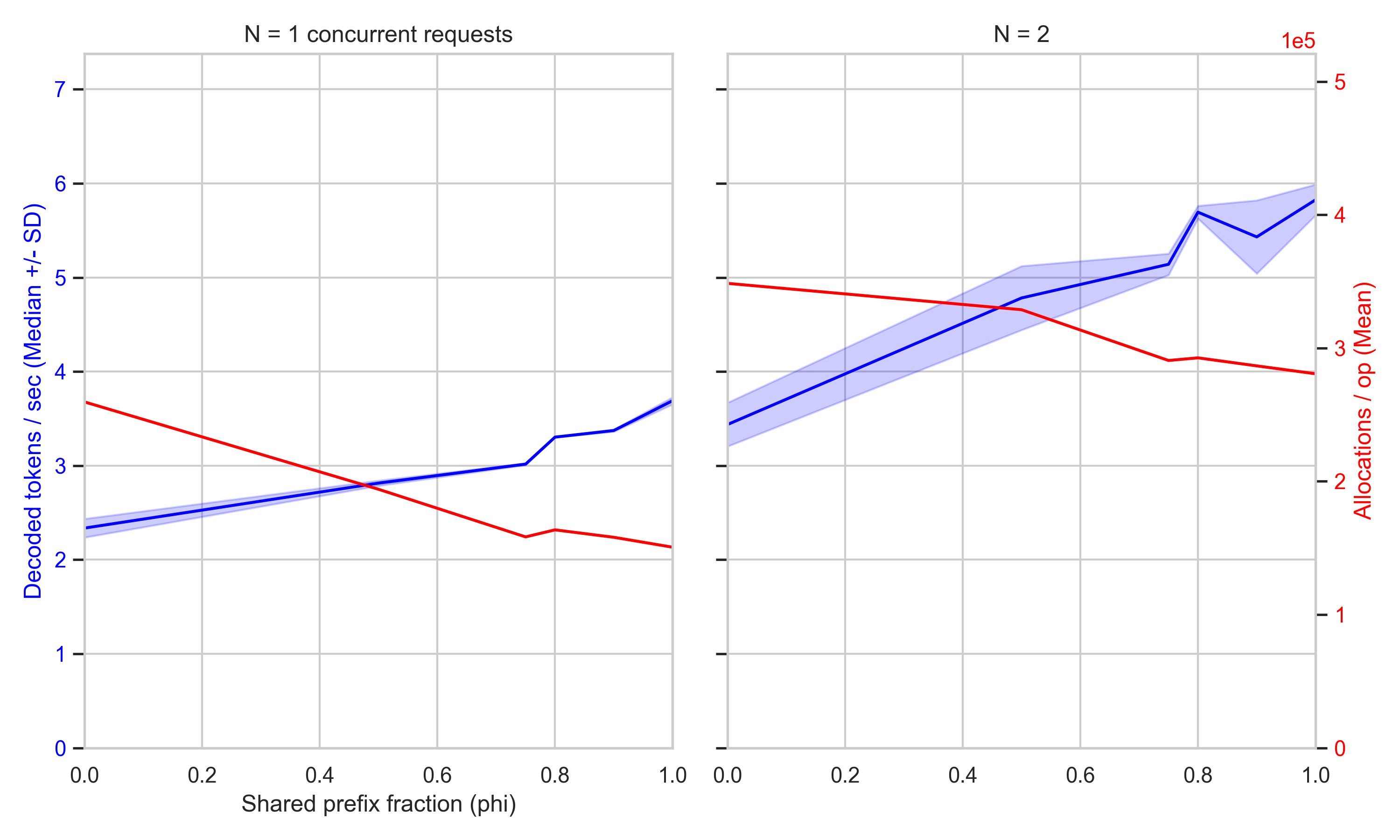
How much do we gain in terms of generation throughput and memory allocation by using RadixAttention with prompts that share a common prefix? Turns out, quite a bit.
The allocations curve (the red trace) shows that caching works as designed : as \(\phi\) rises, the number of heap allocations per iteration falls monotonically, since a larger share of the prefix blocks are acquired from the pool (a refcount bump) rather than allocated fresh, and the prefill positions that those blocks cover no longer have to be recomputed.
Reassuringly, the throughput curve (in blue) also improves linearly with increasing \(\phi\) since cached KV positions need not be prefilled (the fluctuations at \(\phi\) 0.75 and 0.9 are likely due to a noisy benchmarking environment).
N = 4 concurrent requests show the limitations of the benchmark environment, as it appears that the threads starve each other of resources.
Time-to-first-token
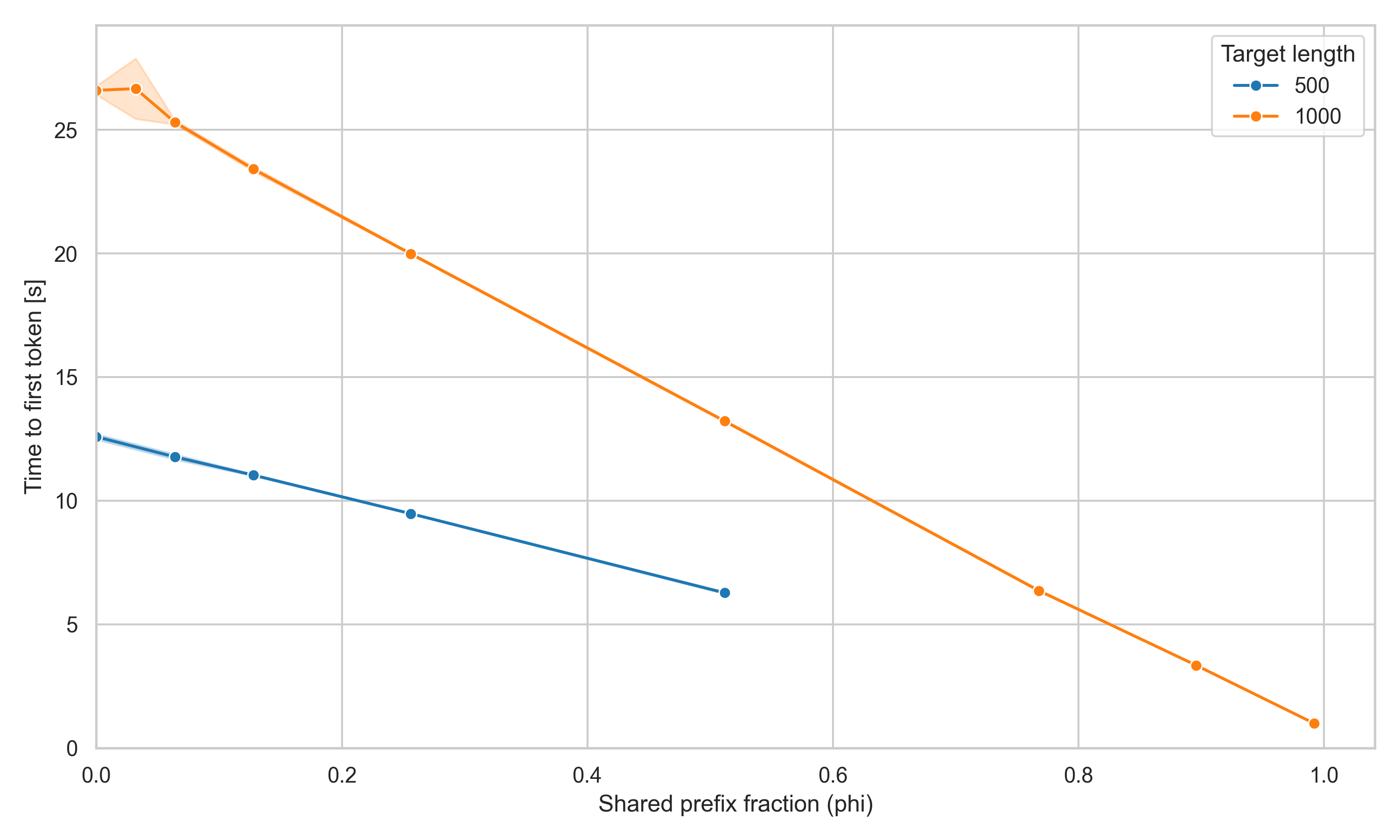
Here we want to measure how much does RadixAttention improve latency when prompt prefixes are shared across LLM calls.
TTFT is measured by prewarming the cache with one prompt, then decoding one token for a single request (concurrency = 1). TTFT falls steadily as \(\phi\) rises, because a larger shared prefix means more positions are served from cached blocks and fewer are prefilled from scratch.
Two notes on reading this figure. First, the large variance at low values of \(\phi\) is a first-iteration artifact : the very first iteration pays a one-time cold-start cost. Note that even at the right end of the grid the maximum achievable hit rate is \( (L/32 − 1)/(L/32) \), not 1.0; the probe prompt always diverges from the warm prompt in its final block, so one block is never shared.
Conclusion
In this post we demonstrated how RadixAttention lets Trellis nodes run up to 80% faster in the single-process case and use 40% less memory, in realistic prompting setups ; these advances are likely to compound as the trend of longer LLM sessions continues.
Trellis is still in its early days, and the design space of a distributed, concurrent LLM runtime is large. If you have thought about this kind of problems before and wish to share some feedback, we would love to hear from you!
Appendix : Choosing a cache block size
We choose the block size heuristically, to balance bookkeeping of the radix tree and latency.
The next figure helped us pick a default block size \(B = 32\) .
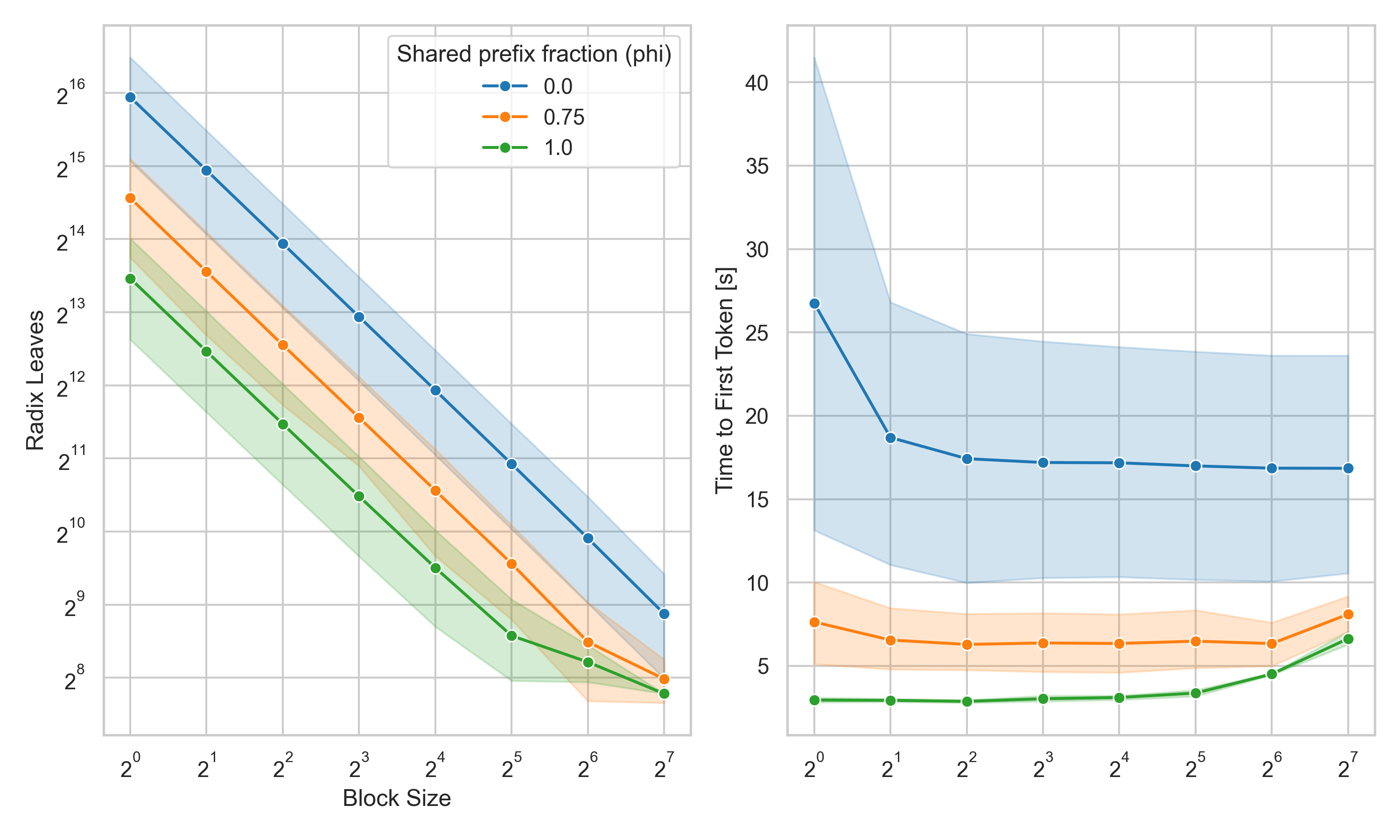
Block size under cache pressure
In this section we focus on the "saturated" pool regime : to force it, we cap the KV cache at a fixed total token capacity (held constant across block sizes, so that \(NumBlocks \propto capacity/B\) and the comparison is fair) and stream a rolling queue of sessions through a small concurrency window, ending each as it completes. Finished sessions leave blocks in the cache; later sessions reclaim them by eviction while the hot shared prefix survives. In this scenario, block size B controls how gracefully the cache evicts.
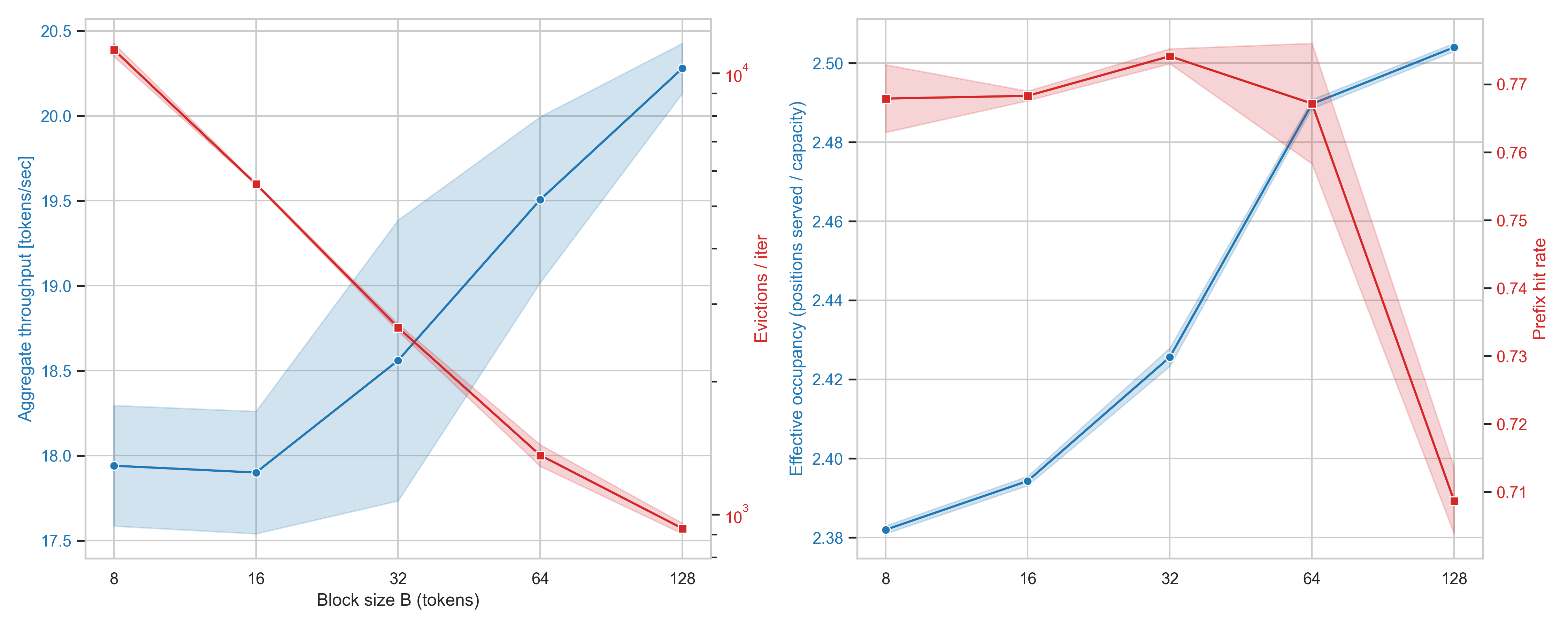
Two effects pull against each other (left panel). At the fine end, eviction count scales as roughly \(1/B\) so small blocks pay a steep LRU- and prefix churn tax, and aggregate throughput is correspondingly lowest there. At large B values, the cost is reuse: each block wastes up to \(B - 1\) positions in a session's suffix. The effective occupancy (useful positions served per unit capacity) actually rise with \(B\), because the shared prefix can be packed into fewer, coarser blocks.